For a long time, I have wanted to run a neural net on an Arduino UNO, but when you start looking for libraries, you will find that most of them only work on the more powerful Arduino boards, and not the UNO.
Because of that and because I thought it would be fun, I decide to write my own simple neural net from scratch, and Today I will show you that code and how it works, so you can use it or create your own code.
Two Steps
There is two major things, we are going to have to do.
First, we will need to create the basic neural net and the algorithm that runs it. For this code, we are creating a net with 2 input nodes, 2 hidden nodes, and 2 output nodes.
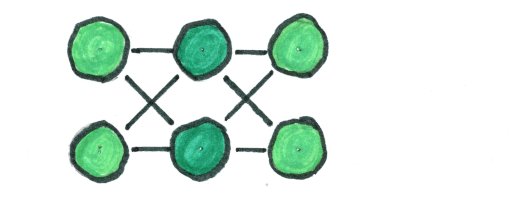
Then, we will need to create the training algorithm. This is normally the hard part, so I kept this algorithm as simple as possible.
Creating The Net
The actual net is really easy to create. It’s just a bunch of variables.
double hidden[2];
double output[2];
double weightH[2][2]; // weights for hidden nodes
double biasH[2]; // hidden node biases
double weightO[2][2]; // weights for output nodes
double biasO[2]; // output node biasesIf we just left those variables with random values, it could cause the net to behave weirdly, so we can use the following function to set the default values.
void setup_net() {
for (int i = 0; i < 2; i++) {
biasO[i] = 0;
biasH[i] = 0;
for (int j = 0; j < 2; j++) {
weightH[i][j] = 0.1;
weightO[i][j] = 0.1;
}
}
}Running the net is also pretty simple, but before we do that we need to create a new function.
double sigmoid(double num) {
return 1 / (1 + exp(-num));
}The sigmoid is a math function, which has some unique properties, in particular the output of it is always greater than 0 and smaller than 1.
Using a sigmoid or some similar function, can dramatically increase the power of your net, but it’s totally optional.
Here is the function that actually runs the neural net.
void run_network(double* input) {
for (int i = 0; i < 2; i++) {// loop through hidden nodes
double val = biasH[i]; //add bias to value
for (int j = 0; j < 2; j++) { //loop thought input nodes
val += input[j] * weightH[i][j];//add (input node)*(its weight) to value
}
hidden[i] = sigmoid(val);
}
for (int i = 0; i < 2; i++) {// loop through output nodes
double val = biasO[i]; //add bias to value
for (int j = 0; j < 2; j++) { //loop thought hidden nodes
val += hidden[j] * weightO[i][j];//add (hidden node)*(its weight) to value
}
output[i] = sigmoid(val);
}
}Training the Net
There are four functions, we will need to create to train our net. We will start with this one.
double single_train(double* input, double* desired) {
run_network(input);
backpropigate(input, desired);
double loss = loss_function(output[0], desired[0]);
loss += loss_function(output[1], desired[1]);
return loss;
}As this function’s name suggests, its job is to take one set of inputs and one set of outputs, and train the net from them.
You may have noticed the loss_function. Because neural nets rarely are a 100% accurate, we need a way to judge if the network is accurate enough, which is where the loss_function comes in. Here is the one I am using.
double loss_function(double value, double desired) {
return (value - desired) * (value - desired);
}You also might have noticed the backpropigate() function. It’s the heart of the training process. Here is what it looks like.
void backpropigate(double* input, double* desired) {
double output_err[2];
for (int i = 0; i < 2; i++) { // loop through output nodes
output_err[i] = (desired[i] - output[i]);
biasO[i] += training_speed * output_err[i];
for (int j = 0; j < 2; j++) { // loop thought connections
weightO[i][j] += training_speed * hidden[i] * output_err[i];
}
}
for (int i = 0; i < 2; i++) { // loop through hidden nodes
float hidden_err = weightO[0][i] * output_err[0] + weightO[1][i] * output_err[1];
biasH[i] += training_speed * hidden_err;
for (int j = 0; j < 2; j++) { // loop thought connections
weightH[i][j] += training_speed * input[i] * hidden_err;
}
}
}What the above function does is loop through every weight and bias in the system, and it changes each one based roughly on the following equation.
effect_on_output * needed_change * training_speedeffect_on_output has to be recalculated for each weight and bias. There is two ways to do that calculation. You could ether change the weight or bias by a small amount e.g. 0.0001 and then see how much the output changes, or you could use calculus. The code above uses the calculus method.
needed_change is different from node to node, but there is a lot of repeats. For this net we only need to calculate it twice. I stored those two values in the array output_err.
For complicated neural nets, training speed can change as the program runs, but it does not need to, so for this program I just defined it at the start of the program like this.
#define training_speed 0.1Training in Bulk
Up to this point, we have all the stuff needed to train one piece of data into our net, but most of the time, we want to be able to train a lot of data into the net, so we need one more function.
double list_train(double input[][2], double desired[][2], int length) {
double loss;
for (int j = 0; j < MAX_LOOPS_FOR_LIST; j++) {
Serial.println();
for (int x = 0; x < MAX_LOOP; x++) {
Serial.print(".");
loss = 0;
for (int i = 0; i < length; i++) {
loss += single_train(input[i], desired[i]);
}
loss /= length;
if (loss <= MAX_ERROR)break;
}
Serial.println();
Serial.print("Loss: ");
Serial.println(loss, DEC);
if (loss <= MAX_ERROR)break;
}
return loss;
}To make this function work, you give it a list of inputs and a list of desired outputs, and it trains the net for each pair of inputs and outputs.
It then repeats that process MAX_LOOP times and prints out the current loss of the net. It then repeats that whole process MAX_LOOPS_FOR_LIST times.
As a reminder as the loss number gets smaller, it means are net is getting more accurate, so while the network is running all of those loops, it’s also checking the loss variable, and if it ever dips below MAX_ERROR, the computer stops training because the net is accurate enough.
All of the MAX_LOOP, MAX_ERROR and so on, need to be define at the begining of the program like this.
#define MAX_LOOP 50
#define MAX_ERROR 0.00001
#define MAX_LOOPS_FOR_LIST 200Full Code
You now have a working neural net, but to be complete, here is all the code combined, plus a little extra code to show how you can run the net.
#define training_speed 0.1
#define MAX_LOOP 50
#define MAX_ERROR 0.00001
#define MAX_LOOPS_FOR_LIST 200
double sigmoid(double num) {
return 1 / (1 + exp(-num));
}
double loss_function(double value, double desired) {
return (value - desired) * (value - desired);
}
//------------ setting up net-------------------------------
double hidden[2];
double output[2];
double weightH[2][2]; // weights for hidden nodes
double biasH[2]; // hidden node biases
double weightO[2][2]; // weights for output nodes
double biasO[2]; // output node biases
void run_network(double* input) {
for (int i = 0; i < 2; i++) {// loop through hidden nodes
double val = biasH[i]; //add bias to value
for (int j = 0; j < 2; j++) { //loop thought input nodes
val += input[j] * weightH[i][j];//add (input node)*(its weight) to value
}
hidden[i] = sigmoid(val);
}
for (int i = 0; i < 2; i++) {// loop through output nodes
double val = biasO[i]; //add bias to value
for (int j = 0; j < 2; j++) { //loop thought hidden nodes
val += hidden[j] * weightO[i][j];//add (hidden node)*(its weight) to value
}
output[i] = sigmoid(val);
}
}
void setup_net() {
for (int i = 0; i < 2; i++) {
biasO[i] = 0;
biasH[i] = 0;
for (int j = 0; j < 2; j++) {
weightH[i][j] = 0.1;
weightO[i][j] = 0.1;
}
}
}
//------------done setting up net----------------------------
//---------------training code-------------------------------
void backpropigate(double* input, double* desired) {
double output_err[2];
for (int i = 0; i < 2; i++) { // loop through output nodes
output_err[i] = (desired[i] - output[i]);
biasO[i] += training_speed * output_err[i];
for (int j = 0; j < 2; j++) { // loop thought connections
weightO[i][j] += training_speed * hidden[i] * output_err[i];
}
}
for (int i = 0; i < 2; i++) { // loop through hidden nodes
float hidden_err = weightO[0][i] * output_err[0] + weightO[1][i] * output_err[1];
biasH[i] += training_speed * hidden_err;
for (int j = 0; j < 2; j++) { // loop thought connections
weightH[i][j] += training_speed * input[i] * hidden_err;
}
}
}
double single_train(double* input, double* desired) {
run_network(input);
backpropigate(input, desired);
double loss = loss_function(output[0], desired[0]);
loss += loss_function(output[1], desired[1]);
return loss;
}
double list_train(double input[][2], double desired[][2], int length) {
double loss;
for (int j = 0; j < MAX_LOOPS_FOR_LIST; j++) {
Serial.println();
for (int x = 0; x < MAX_LOOP; x++) {
Serial.print(".");
loss = 0;
for (int i = 0; i < length; i++) {
loss += single_train(input[i], desired[i]);
}
loss /= length;
if (loss <= MAX_ERROR)break;
}
Serial.println();
Serial.print("Loss: ");
Serial.println(loss, DEC);
if (loss <= MAX_ERROR)break;
}
return loss;
}
//---------------done with training code---------------------
void setup() {
Serial.begin(9600);
setup_net();
double inputs[2][2] = {
{0.1, 0.1},
{0.3, 0.3}
};
double outputs[2][2] = {
{0.6, 0.6},
{0.8, 0.4}
};
list_train(inputs, outputs, 2);
Serial.println("---Testing Net---");
for (int i = 0; i < 2; i++) {
run_network(inputs[i]);
Serial.print("Input: ");
Serial.print(inputs[i][0]);
Serial.print(", ");
Serial.print(inputs[i][1]);
Serial.print(" Output: ");
Serial.print(output[0]);
Serial.print(", ");
Serial.print(output[1]);
Serial.print(" Desired: ");
Serial.print(outputs[i][0]);
Serial.print(", ");
Serial.println(outputs[i][1]);
}
}
void loop() {
}If you like seeing how computer algorithms work, you might like to see the algorithms that makes robots draw straight lines.